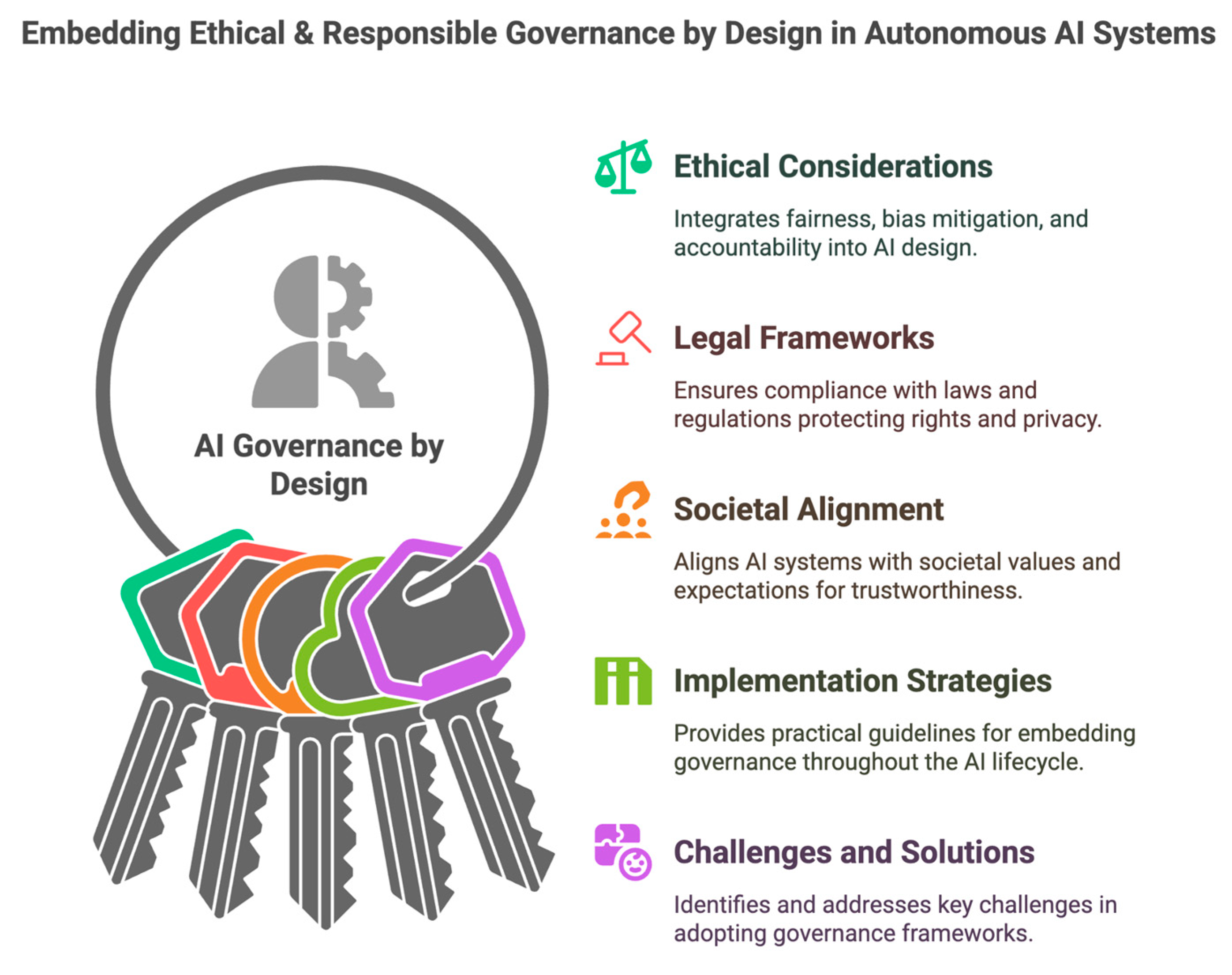
GlossAPI and the Swiss AI Initiative: a strategic investment in Greek as public digital infrastructure

An approval that changes the scale of ambition The approval of the proposal “Enhancing multilingual foundation models through lexicographic grounding: advancing GlossAPI for Apertus Greek language integration” by the Swiss AI Initiative is more than a welcome grant decision. It is a recognition that Greek should be treated as critical digital infrastructure in the age … Read more