


From PHAROS to local models: a layered architecture for open AI
The right strategy for artificial intelligence is not to choose one single technological solution. Not everything needs to run on a supercomputer, and it is equally unreasonable for every public body, university, school or business to depend permanently on commercial cloud APIs. The rational approach is layered: national high-performance computing infrastructure for heavy workloads, local open infrastructure for secure everyday use, and alternative hardware platforms to avoid a new form of technological lock-in.
PHAROS and DAEDALUS belong to the first layer. They are national infrastructures for large-scale tasks: training or substantial adaptation of large models, benchmarking Greek language models, creating and validating high-quality datasets, scientific simulations, applications in health, culture, climate and sustainability, and support for research teams and start-ups that need compute capacity beyond the reach of a single organisation. This is the role of the supercomputer: it creates, tests, compares and improves models.
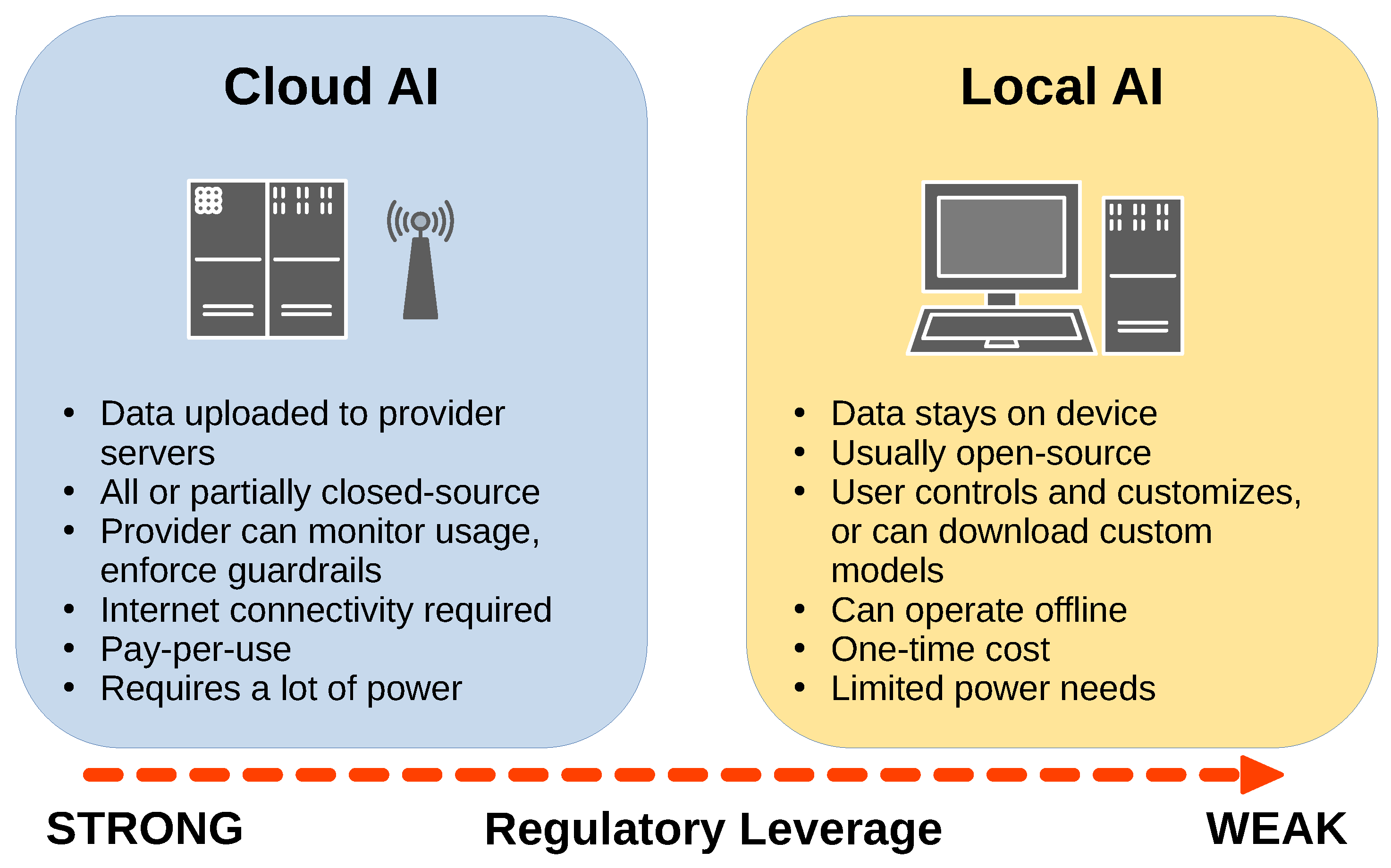
The second layer is local open-source AI. Here the goal is not to train a huge model from scratch, but to run a secure, affordable and auditable AI service close to the data. A pilot deployment may use, for example, two Apple Mac Studio M3 Ultra nodes with 256 GB unified memory and two NVIDIA DGX Spark GB10 nodes with 128 GB unified memory, 4 TB NVMe storage per node, and support for Metal, CUDA, llama.cpp, vLLM and TensorRT-LLM. The Apple nodes are well suited for low-power always-on inference, small and medium models, embeddings, document search, summarisation, transcription and privacy-sensitive workflows. The NVIDIA nodes cover heavier inference, larger models, batch processing and more demanding experimentation.
The third layer, which is becoming increasingly important, is the AMD/ROCm ecosystem. AMD now offers an alternative path for low-cost open LLMs, both in data centres and in local deployments. At the data centre level, AMD Instinct MI300X, MI325X and MI350 are relevant mainly because of their very large memory per accelerator: 192 GB HBM3 on MI300X, 256 GB HBM3E on MI325X and up to 288 GB HBM3E on the MI350 series. For large open models, memory is a key cost factor. When more parameters fit on one GPU or on fewer GPUs, complexity, interconnect requirements, power consumption and total cost of ownership can be reduced.
The value of the AMD ecosystem is not only in hardware. It is also in ROCm, AMD’s open source software stack for accelerated AI and HPC computing. ROCm documentation now describes support for major LLM serving engines, including vLLM and Hugging Face Text Generation Inference. At the same time, tools such as llama.cpp, Ollama, Vulkan and HIP/ROCm enable heterogeneous deployments, where different hardware can be used depending on the workload. This matters for organisations that do not want to be locked into a single vendor chain.
In practice, a mature strategy for low-cost open LLMs should not be framed as “NVIDIA or AMD”, “Apple or data centre”, “PHAROS or local node”. It should be combined. PHAROS and DAEDALUS should be used for heavy training, evaluation and national model infrastructure. Local NVIDIA and Apple nodes should be used for immediate, reliable and secure inference inside organisations. AMD/ROCm solutions add competition, large memory per GPU, potential cost advantages and an alternative open software ecosystem.
This is especially important for public administration, businesses and education. A municipality, university or hospital can use local models for everyday tasks such as regulatory search, document summarisation, request classification, user support and secure access to internal knowledge. A ministry or research centre can use PHAROS for larger experiments and evaluations. A small or medium-sized enterprise can start with a workstation or small local node and later scale to a data centre. What matters is that the architecture is based on open standards, open models where possible, interchangeable backends and publicly accountable governance.
This avoids two mistakes. The first is the illusion that everything must be solved by one central super-system. The second is dependence on thousands of disconnected small solutions without common standards, security or evaluation. Democratic artificial intelligence needs central compute power where it is necessary, local control where it is critical, and an open hardware and software ecosystem so that public money builds public capability.